
Introduction to Machine Learning
Machine learning is a subfield of artificial intelligence that focuses on the development of algorithms and statistical models that enable computers to perform tasks without explicit instructions. Instead of being programmed to accomplish specific tasks, these systems learn from and make predictions based on data. In recent years, machine learning has gained immense significance across various sectors, including healthcare, finance, and marketing, revolutionizing how businesses operate and make data-driven decisions.
The rise of big data has further fueled the adoption of machine learning techniques, as organizations have access to vast amounts of data that can be harnessed to uncover patterns and insights. This evolution in technology has enabled companies to improve their products and services, enhance customer experiences, and increase operational efficiency. For instance, in healthcare, machine learning algorithms are used to analyze medical images and predict disease outbreaks, significantly improving patient outcomes.
Moreover, the transformative impact of machine learning is evident in the way it empowers organizations to anticipate trends and automate processes. The development of tools that leverage machine learning allows businesses to segment their customer base, tailor marketing strategies, and optimize supply chains. This ongoing innovation underscores the importance of understanding key concepts within the field, such as supervised and unsupervised learning.
Understanding these concepts is essential for leveraging machine learning effectively. Supervised learning involves training a model on labeled data, allowing it to learn from previous examples, whereas unsupervised learning seeks to find patterns within unlabeled data. By exploring these approaches, businesses can deploy machine learning solutions that meet their specific needs and objectives, thereby harnessing the full potential of this technology in the modern landscape.
What is Supervised Learning?
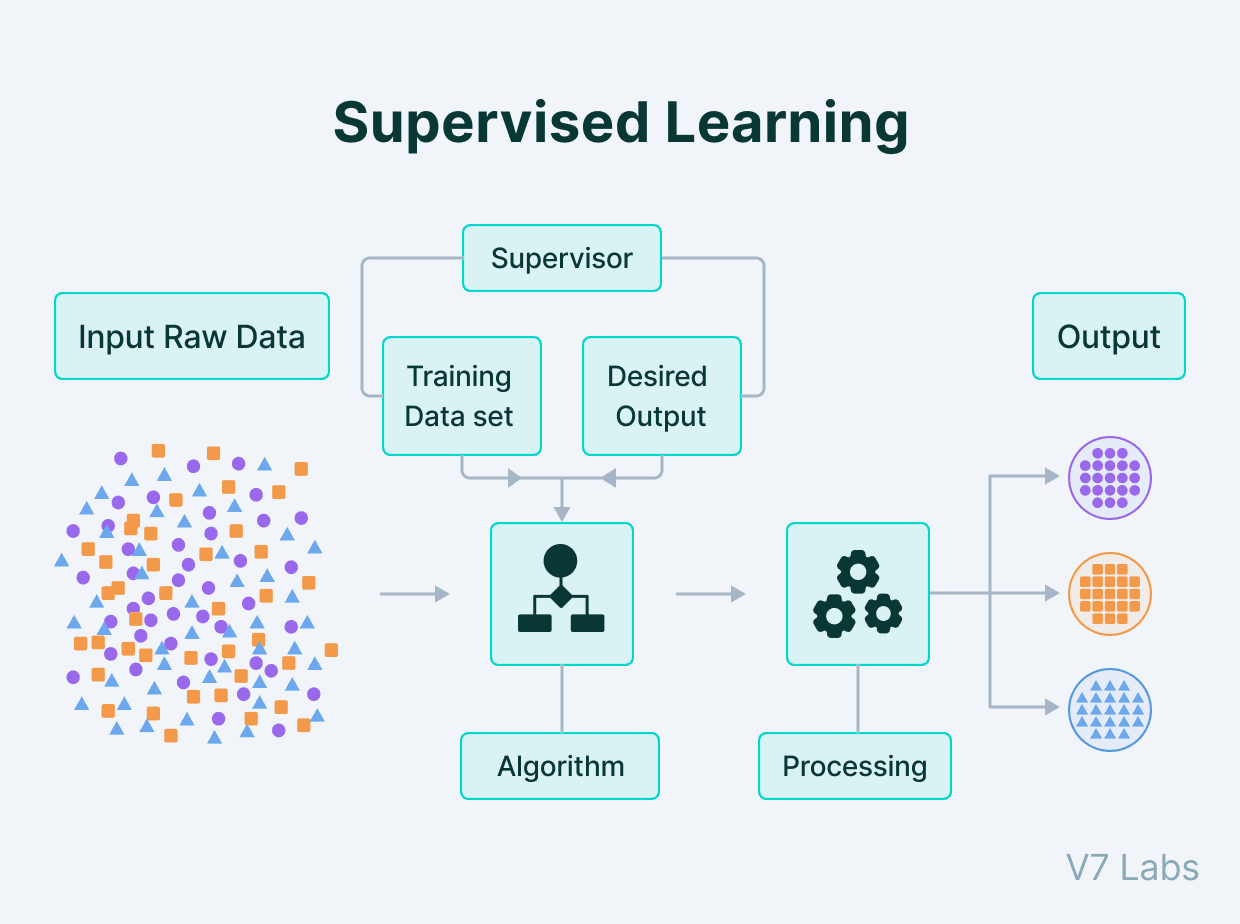
Supervised learning is a fundamental machine learning paradigm wherein an algorithm is trained using a labeled dataset. In this context, “labeled” refers to data that has been annotated with the correct output or target variable, providing the model with input-output pairs that facilitate learning. The primary objective of supervised learning is to enable the algorithm to make accurate predictions or classifications when presented with new, unseen data. By leveraging the guidance from labeled data, the model develops a mapping between the input features and the corresponding outputs.
During the training phase, the supervised learning algorithm iteratively adjusts its internal parameters based on the errors it makes in predicting the target variable. This process involves minimizing a loss function that quantifies the difference between the predicted and actual values. Common loss functions include mean squared error for regression tasks and cross-entropy loss for classification tasks. Once adequately trained, the model can generalize from the training data to new inputs, making it capable of predicting outcomes effectively.
Numerous applications of supervised learning exist across various sectors. For instance, in classification tasks, supervised learning algorithms are employed in spam detection, where emails are classified as either spam or not spam based on labeled examples. Additionally, in regression tasks, these algorithms predict continuous values, such as housing prices or stock market trends, by learning from historical data. Furthermore, with advancements in supervised learning techniques, this methodology continues to drive innovation in areas such as medical diagnosis, where algorithms assist in identifying diseases based on patient data. Thus, supervised learning serves not only as a foundational concept in machine learning but also as a powerful tool for solving real-world problems.
What is Unsupervised Learning?
Unsupervised learning is a type of machine learning that operates without the guidance of labeled data. Unlike supervised learning, where the model is trained on a dataset containing inputs and their corresponding outputs, unsupervised learning focuses on identifying patterns and structures within an unlabelled dataset. This process allows the system to learn the inherent relationships among the data points independently, making it particularly useful for tasks where labeled data is scarce or unavailable.
The main purpose of unsupervised learning is to uncover hidden structures in data, which can be utilized for various applications. Two primary techniques used in unsupervised learning are clustering and association. Clustering involves grouping a set of objects in such a way that objects in the same group (or cluster) are more similar to one another than to those in other groups. This method is commonly employed for customer segmentation, where businesses analyze consumer data to identify distinct groups based on purchasing behavior, preferences, or demographics.
Another important aspect of unsupervised learning is association, which seeks to discover rules that describe large portions of the data. A popular example of this is market basket analysis, where unsupervised learning techniques are employed to determine the purchasing behavior of customers. By examining transactional datasets, businesses can identify patterns, such as which products are frequently bought together, allowing for strategic product placements and promotions that enhance sales.
Overall, unsupervised learning provides a powerful approach to data analysis, enabling organizations to gain insights and make informed decisions without the necessity of labeled training data. Its applications span a wide range of fields, including marketing, healthcare, and finance, underscoring its significance in extracting valuable information from complex datasets.
Key Differences Between Supervised and Unsupervised Learning
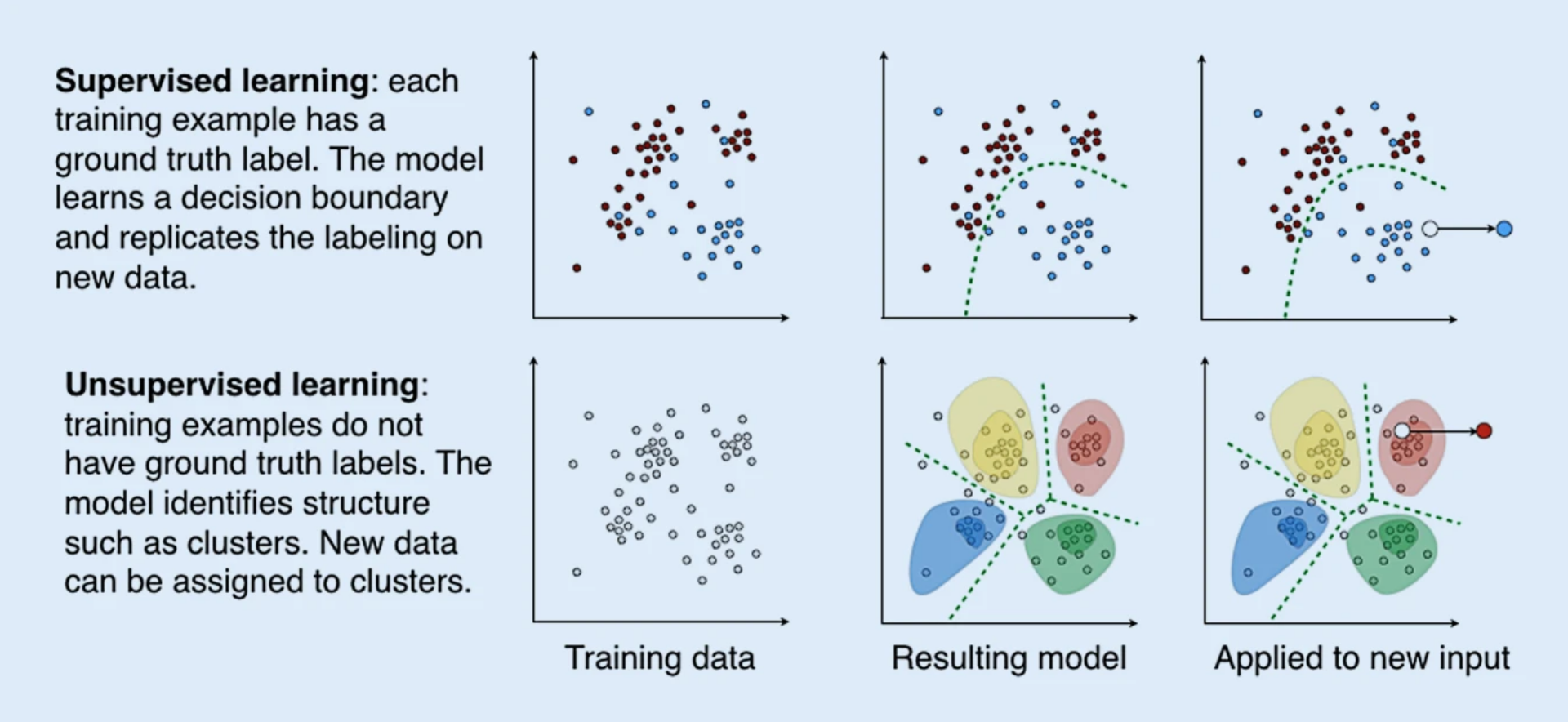
Supervised and unsupervised learning are two primary paradigms in the field of machine learning, each with distinct objectives and methodologies that cater to different types of data analysis. Understanding the key differences can help in selecting the appropriate approach for specific tasks.
First, the objectives of these learning methods differ significantly. Supervised learning primarily aims to predict outcomes based on labeled input data. This means that the model is trained using a dataset that includes both the input features and the correct output, allowing for a direct relationship to be established. In contrast, unsupervised learning focuses on identifying patterns and structures within unlabeled data. Here, the model seeks to group data points or reduce dimensionality without prior knowledge of the outcomes.
When it comes to data requirements, supervised learning necessitates a well-structured dataset with both features and labeled outcomes. This often requires substantial time and effort in data annotation and preparation. Conversely, unsupervised learning utilizes datasets without label specifications, making it more flexible in terms of data availability, but potentially challenging in terms of gleaning actionable insights.
The methodologies employed also differ. Supervised learning algorithms typically include linear regression, logistic regression, support vector machines, and various neural networks. In comparison, unsupervised techniques might include clustering algorithms like K-means, hierarchical clustering, and dimensionality reduction methods such as Principal Component Analysis (PCA).
Finally, the outcomes of both types of learning are inherently different. Supervised learning results in predictive models that can classify or make forecasts, while unsupervised learning outcomes often involve cluster categorization or new data representation that reveals underlying relationships.
The choice between supervised and unsupervised learning largely depends on the problem at hand, the data available, and the specific objectives set out for data analysis. Understanding these distinctions is crucial for effectively applying machine learning techniques in practice.
Advantages and Disadvantages of Supervised Learning
Supervised learning is a prominent approach in the field of machine learning, characterized by the use of labeled datasets to guide the algorithm in making predictions or decisions. One of the primary advantages of supervised learning is its high accuracy, particularly when the training data is representative of the real-world scenarios the model will encounter. This accuracy stems from the model’s direct correlation with the labeled data, which enables it to learn from specific examples, thus providing predictable outcomes in similar cases.
Moreover, supervised learning algorithms typically excel at classification and regression tasks, making them versatile for various applications, such as fraud detection, market analysis, and image recognition. The availability of robust frameworks and libraries further enhances the efficiency of implementing supervised methods, facilitating faster development cycles and iterations.
Despite its benefits, supervised learning presents notable disadvantages. The foremost limitation is the necessity for labeled data, which can be resource-intensive and time-consuming to acquire. In many scenarios, especially those involving vast amounts of data, obtaining sufficient labeled examples may not be feasible, leading to incomplete training datasets and less effective models.
Another concern is the risk of overfitting, wherein the model performs exceedingly well on the training data but fails to generalize to unseen data. This occurs when a model learns the noise and specifics of the training set rather than the underlying trends, resulting in poor predictive performance in real-world applications. To mitigate this, practitioners often employ techniques such as regularization and cross-validation; however, these solutions add complexity to the model development process.
In consideration of these advantages and disadvantages, it is crucial for practitioners to weigh the outcomes of supervised learning approaches against their operational contexts, ensuring that the benefits effectively align with the intended applications.
Advantages and Disadvantages of Unsupervised Learning
Unsupervised learning presents a unique set of advantages and disadvantages that can significantly impact its effectiveness in various applications. One of the primary strengths of unsupervised learning is its ability to identify hidden patterns and structures in datasets without the necessity for labeled data. This characteristic makes it especially valuable in scenarios where acquiring labeled data is challenging or expensive. Algorithms such as clustering, dimensionality reduction, and association analysis allow practitioners to explore and analyze data, revealing insights that would otherwise remain obscured.
Additionally, unsupervised learning can facilitate the discovery of natural groupings, enhancing understanding of the data’s intrinsic characteristics. For instance, businesses use clustering techniques to segment customers based on purchasing behavior, allowing for more targeted marketing strategies. These insights can lead to innovative solutions, improving decision-making processes across various domains, including healthcare, finance, and social sciences.
However, unsupervised learning is not without its challenges. One significant disadvantage is the difficulty in evaluating the performance and outcome of unsupervised algorithms. Unlike supervised learning, where results can be measured against known labels, unsupervised learning lacks such benchmarks, making it harder to validate the findings. This uncertainty can lead to ambiguous outputs, where the interpretations of patterns may vary among analysts, potentially resulting in misinformed decisions.
Moreover, the complexity of the data can influence the algorithm’s ability to derive meaningful insights. High-dimensional data might lead to the curse of dimensionality, where the effectiveness of certain techniques diminishes. Careful preprocessing and feature selection become crucial to optimize the performance of unsupervised learning models. In summary, while unsupervised learning offers innovative pathways to analyze data, it requires careful consideration of its limitations to maximize its potential benefits.
When to Use Supervised vs. Unsupervised Learning
Choosing between supervised and unsupervised learning methodologies depends on various factors, including the nature of the data available, project objectives, and desired outcomes. One of the most crucial considerations is the availability of labeled data. In supervised learning, algorithms are trained on labeled datasets where the input features are paired with the correct output labels. This approach is highly effective for tasks such as classification and regression, where the objective is to predict outcomes based on input variables. If a project provides a significant amount of labeled data, then supervised learning is often the preferred choice due to its predictive accuracy and performance.
Conversely, unsupervised learning is applicable in scenarios where labeled data is scarce or non-existent. This methodology focuses on discovering patterns and relationships within the input data without explicit supervision. Clustering and dimensionality reduction techniques are common in unsupervised learning and are valuable for exploratory data analysis, anomaly detection, or understanding the underlying structure of data. If the primary goal is to gain insights or to derive information from unstructured data, unsupervised learning strategies become relevant.
Additionally, the specific goals of the analysis play a pivotal role in determining the appropriate learning method. If the aim is to develop a model that generalizes well to new, unseen data, then supervised learning might be best suited. However, if the objective is to uncover hidden trends or partitions within the dataset, unsupervised learning can provide significant insights. As such, understanding the context, data characteristics, and analysis goals is essential for making informed decisions regarding the application of supervised versus unsupervised learning techniques.
Real-World Applications of Supervised and Unsupervised Learning
In today’s data-driven landscape, both supervised and unsupervised learning techniques are pivotal in various industries, including finance, healthcare, and e-commerce. These approaches leverage complex algorithms to analyze vast amounts of data, turning it into actionable insights.
In the finance sector, supervised learning plays a crucial role in credit scoring and risk assessment. By training algorithms on historical lending data that includes features such as income levels, credit reports, and repayment history, financial institutions can accurately predict the likelihood of default. This not only streamlines the decision-making process but also minimizes financial risk. For instance, banks utilize supervised algorithms to flag fraudulent activities by identifying patterns in transaction data that deviate from the norm.
Conversely, unsupervised learning finds its application in customer segmentation within the e-commerce industry. By analyzing customer behavior and purchasing patterns without labeled outcomes, companies can categorize users based on their preferences. This helps in crafting tailored marketing strategies, enhancing user experience, and ultimately driving sales. Retail giants employ clustering techniques to identify groups of customers with similar buying habits, enabling personalized recommendations that are more likely to convert into sales.
In healthcare, supervised learning is often applied in diagnostic imaging, where algorithms are trained on labeled datasets consisting of various images to identify diseases such as cancer with precision. The ability to predict medical conditions based on previous cases significantly enhances early intervention, improving patient outcomes. Meanwhile, unsupervised learning techniques aid in drug discovery by clustering similar compounds, thereby accelerating research processes and facilitating the identification of promising candidates.
Both supervised and unsupervised learning methodologies demonstrate their immense practical significance across these industries, evident in their capacity to drive innovation and efficiency. As technology advances, the integration of these approaches will undoubtedly reshape how organizations harness data to solve complex challenges.
Conclusion and Future Trends in Machine Learning
As explored throughout this blog post, supervised and unsupervised learning represent two fundamental approaches within the realm of machine learning. Supervised learning, characterized by labeled data, enables the development of predictive models through explicit guidance during the training phase. It is particularly effective in applications such as classification and regression tasks, where the aim is to predict outcomes based on input variables. In contrast, unsupervised learning operates on unlabeled data, allowing algorithms to identify patterns and groupings autonomously. This approach excels in scenarios like clustering and anomaly detection, revealing insights that may go unnoticed in a supervised framework.
Both learning paradigms have their unique strengths and applications depending on the nature of the dataset and the specific problem being addressed. In recent years, the convergence of these methods has given rise to semi-supervised and self-supervised learning, which merge elements of both supervised and unsupervised techniques. These evolving approaches are particularly useful in situations where acquiring labeled data is costly or impractical, thereby enhancing the efficiency of machine learning models.
Looking ahead, there are several emerging trends poised to shape the future of these learning methodologies. One significant trend is the increasing integration of deep learning techniques, which combine the hierarchical nature of neural networks with both supervised and unsupervised learning principles. Additionally, advancements in transfer learning will further enhance adaptability, enabling models to apply knowledge gained from one domain to other related tasks. As computational resources and data availability continue to expand, the application of machine learning will likely become more pervasive across various industries, leading to novel applications that capitalize on the strengths of both supervised and unsupervised learning. The future of machine learning, therefore, holds exciting potential as these approaches continue to evolve and intersect, driving innovation across numerous fields.