
In the fast-moving world of artificial intelligence, the latest innovations often come with big numbers, complex terminology, and technical bragging rights. But among the many announcements that have recently surfaced, GPT‑OSS‑120B has caught notable attention—and not just among researchers and developers. Whether you’re a tech enthusiast or someone trying to understand how AI continues to change the digital world, this model is something worth exploring. At the center of this breakthrough lies a special type of architecture known as a Mixture-of-Experts (MoE) transformer, which gives GPT‑OSS‑120B its extraordinary capabilities. While that may sound like dense jargon, let’s unpack what makes this model different and why it has become a trending topic in the AI community under the name gpt oss.
First, let’s break down what GPT‑OSS‑120B actually means. The “GPT” part refers to a class of models called Generative Pre-trained Transformers, originally developed by OpenAI and now expanded upon by various organizations. These models are designed to generate human-like text based on the input they receive. The “OSS” in gpt oss is short for “Open Source System” (or sometimes interpreted as Open Source Software), a nod to the model’s accessible nature and modular development. The “120B” refers to its massive parameter size—120 billion parameters in total—making it one of the largest open models available for public and experimental use. Parameters in AI models are like the neurons of the brain; the more you have, the more complex and nuanced the outputs can be. This means GPT‑OSS‑120B can handle far more intricate questions, understand detailed prompts, and even reason in ways smaller models simply can’t.
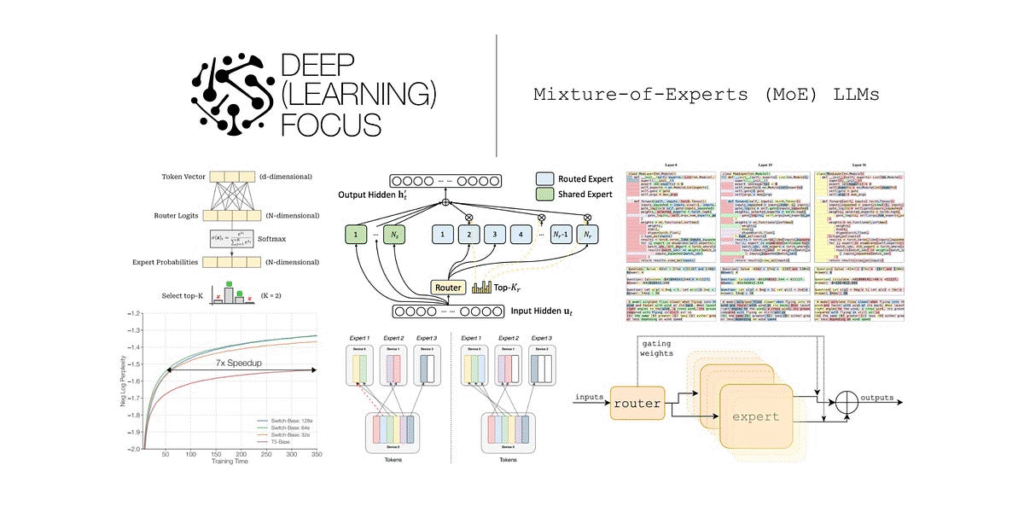
One of the most important features of the GPT‑OSS‑120B model is its 36-layer Mixture-of-Experts (MoE) architecture. Now, if you’re not a machine learning engineer, that phrase might sound intimidating, but it’s actually a clever design that balances performance with efficiency. Think of the model as having multiple “experts”—each one trained to handle different types of tasks or knowledge areas. Rather than activating every single expert every time a word or token is processed, the system only chooses the most relevant ones. Specifically, GPT‑OSS‑120B has 128 experts per layer, but only 4 experts are active per token during inference. This means the model doesn’t waste energy or computing power—just like a wise manager who only brings in the right team members for the right job.
This MoE design is part of what sets gpt oss apart from other large language models. While traditional models activate all their parameters for every input, MoE models like GPT‑OSS‑120B can remain lightweight and faster while still packing in a massive brain. This makes them more efficient for both training and inference, opening the door to real-time applications like customer service bots, programming assistants, and even personalized learning tutors. In benchmarks across coding problems, complex reasoning tasks, and even healthcare questions, GPT‑OSS‑120B performs with surprising accuracy. It shows particular strength in chain-of-thought reasoning, which is a fancy way of saying it can break down complex prompts step-by-step in a way that mimics how humans think through problems.
Another key reason the gpt oss topic is trending is that it appears to signal a move toward more democratized AI development. While many of the most powerful models—like OpenAI’s GPT-4, Google’s Gemini, or Anthropic’s Claude—are kept behind API paywalls and proprietary platforms, GPT‑OSS‑120B is more open in nature. Developers and organizations can experiment with it, tweak its structure, and adapt it to their own needs without waiting for permission or paying premium fees. This opens the door to grassroots innovation and could accelerate the pace of discovery in everything from autonomous robotics to scientific research. The fact that this model was discussed in leaked documents and quietly confirmed in technical circles only adds to its mystique, sparking interest from AI researchers, journalists, and curious hobbyists alike.
On a technical level, the model’s ability to selectively activate a small subset of experts means it’s possible to scale model size without scaling costs proportionally. That’s a game-changer in the field. In typical transformer models, every parameter needs to be involved in generating an output. But with gpt oss, only a fraction of the total network gets used at any given moment—making the model highly scalable, modular, and cost-efficient. So even though GPT‑OSS‑120B is a heavyweight in terms of size, it runs like a lean, well-optimized system in practice. This allows organizations to experiment with frontier models without having to break the bank on cloud compute.
For developers, this presents enormous opportunities. The gpt oss model could be used in coding tools, intelligent search engines, translation platforms, or even AI companions that adapt to different users’ styles. Its architecture also makes it easy to extend—new experts can be added or swapped out depending on the domain or the problem at hand. For example, if you’re building a financial chatbot, you could train specific experts on tax law or investment strategy while keeping the rest of the model general-purpose. That modularity is exactly what’s needed for scalable AI applications in real-world industries.

Of course, with great power comes great responsibility. The release of models like GPT‑OSS‑120B also raises ethical and security concerns. Open access can be a double-edged sword: while it enables innovation, it also makes powerful tools available for misuse. That’s why many experts argue for a balanced approach—providing access while also ensuring transparency and safeguards are in place. Some have proposed “safety rails” in the form of filtered datasets, usage monitoring, or community-driven governance frameworks. If used wisely, gpt oss can be a force for positive change—especially in areas where smaller teams and underfunded research groups can’t afford access to closed-source systems.
What’s exciting is how gpt oss sits at the intersection of high-end AI performance and open community values. It serves as a reminder that not all progress in artificial intelligence needs to be locked away behind corporate gates. The fact that such a powerful model is being discussed openly (and with real documentation to back it up) shows a shift in mindset—towards shared intelligence and collaborative development. Whether you’re an AI builder, a policy thinker, or just someone fascinated by the future of tech, GPT‑OSS‑120B is worth paying attention to.
In summary, the gpt oss topic isn’t just about a new model. It’s a signal that we’re entering a phase where open-source AI is stepping up to compete with the biggest names in the industry. With its 36-layer architecture, 128-expert-per-layer structure, and efficient use of only 4 active experts per token, GPT‑OSS‑120B represents a leap forward in balancing power with practicality. And as more people discover its capabilities and potential, we’re likely to see it become a core building block for a wide range of applications—from next-gen education platforms to smart assistants and beyond. The age of accessible super-intelligence might just be starting, and GPT OSS could very well be leading the way.