
In today’s digital world, information is everywhere. Every time you scroll through social media, send a message, book a cab, or even check the weather, you’re creating data. Most of us never think about where all this information goes, or what happens to it. But behind the scenes, that data is being collected, organized, and used to train machines to think and act more intelligently. This is the world of data science data, and it’s transforming everything from how businesses operate to how we receive medical care.
Let’s take a closer look at how massive amounts of data, often referred to as big data, are shaping the future of smart algorithms and artificial intelligence. This isn’t a story about complex computer science or abstract math. It’s a human story—about how the little bits of information we leave behind each day are powering machines to work smarter, faster, and better for us.
Big Data: The Foundation of Modern Intelligence
Before we can talk about smart algorithms or artificial intelligence, we have to understand the fuel that drives them: big data. Big data refers to extremely large and complex sets of information that are collected from different sources at high speed. These sources can include social media activity, GPS tracking, online transactions, video footage, sensor data, and much more.
What makes big data so valuable is not just its size, but its variety and speed. It’s constantly growing, constantly changing, and full of useful insights. Businesses, governments, and researchers are tapping into these data streams to make smarter decisions, automate tasks, and solve problems in ways that were impossible just a decade ago.
For example, a supermarket might track the items people buy every day. Over time, this data helps the store understand which products are popular, what time people shop the most, and which items are frequently bought together. That’s not just useful—it’s powerful. With that knowledge, the store can adjust its marketing, manage its inventory, and even personalize shopping experiences for customers. This is a small-scale example of what’s happening on a much larger scale all over the world.
Understanding Data Science Data
So, where does data science data come into the picture? Data science is the field that takes raw data and turns it into knowledge. It’s the process of collecting, cleaning, analyzing, and interpreting data to discover patterns and trends. The goal is to find useful insights and make predictions that can help people or businesses make better decisions.
But data science can’t work without data. In fact, data is the lifeblood of this entire process. Whether we’re training a chatbot, building a self-driving car, or predicting the stock market, it all starts with high-quality, diverse, and accurate data. That’s what we call data science data—the raw material that’s used to teach machines how to learn and act.
To give you an idea of just how much data is needed, consider a simple recommendation engine like the one used by Netflix. It doesn’t just guess what shows you might like. It looks at your viewing history, compares it with millions of other users, analyzes what time you watch, what genre you prefer, and how you rate certain shows. The more data it has, the smarter it becomes. Without that data, the algorithm is just a blind guesser.
How Big Data Powers Smart Algorithms
Now let’s talk about the algorithms themselves. Algorithms are sets of instructions or rules that computers follow to solve problems or perform tasks. When we say an algorithm is “smart,” we mean it has been trained using machine learning—a process where the algorithm learns from data instead of being manually programmed for every situation.
Here’s where things get interesting. The more data science data an algorithm has access to, the better it can learn. It’s like teaching a child to read. If you give them one book, they might learn a few words. But if you give them a whole library, they can understand different genres, writing styles, and ideas. Algorithms work the same way. The more examples they see, the more accurate and flexible they become.
Let’s take facial recognition as an example. To accurately identify faces, an algorithm needs to be trained on thousands or even millions of face images—of all ages, skin tones, angles, and expressions. Only then can it learn to recognize faces in the real world. That training data is what makes the algorithm “smart.” Without it, the algorithm is incomplete and often inaccurate.
Real-World Applications of Data-Driven Algorithms
We interact with data-powered algorithms more often than we think. Every time your smartphone unlocks using your face, or your email moves a suspicious message to the spam folder, there’s an algorithm at work. And it was trained using data science data.
One powerful example comes from healthcare. Hospitals are using data to predict patient outcomes, detect early signs of disease, and even recommend treatment plans. Imagine a system that can warn doctors about a potential heart attack before it happens. That system is trained using thousands of patient records—heart rates, blood pressure readings, medical histories, and more. The algorithm finds patterns that even experienced doctors might miss. That’s the power of big data combined with smart algorithms.
Another major field is transportation. Cities around the world are using traffic data to manage congestion, reroute public transit, and improve road safety. Self-driving cars rely on enormous amounts of data—from cameras, sensors, maps, and user inputs—to make decisions in real-time. And behind all this is a network of learning algorithms fueled by high-quality data.
Infographic: The Data Science Cycle
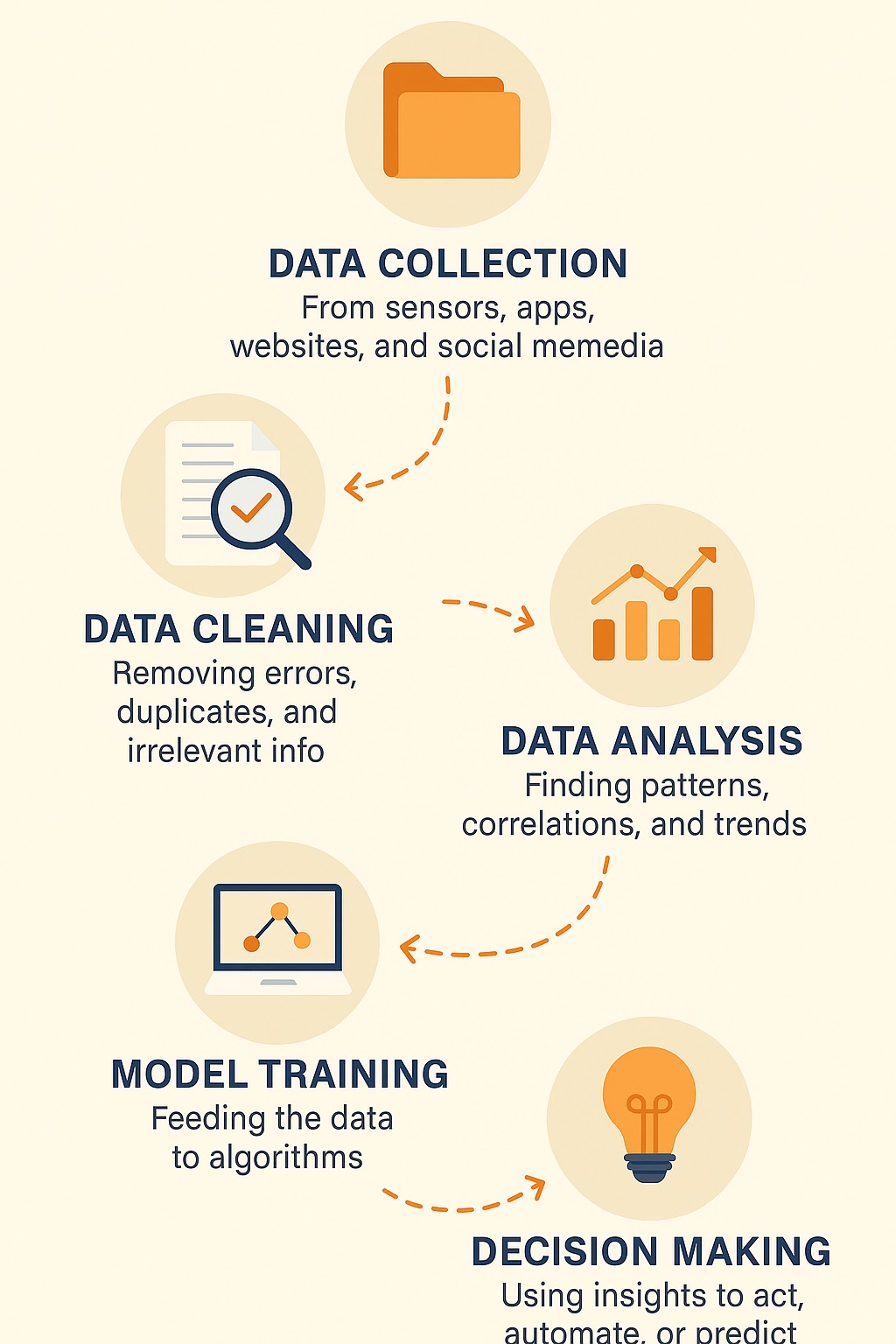
This loop runs in real-time in many industries and makes today’s smart technology possible.
Why Quality of Data Matters
You’ve probably heard the phrase, “Garbage in, garbage out.” This is especially true in data science. The quality of your algorithm depends entirely on the quality of the data you feed it.
If the data is biased, outdated, or inaccurate, your algorithm will reflect those problems. In the real world, this can have serious consequences. For example, a hiring algorithm trained on biased data might discriminate against certain groups. Or a medical diagnostic tool might miss warning signs because its training data didn’t include enough variation.
That’s why data scientists spend so much time cleaning and preparing the data. It’s not just about quantity—it’s about quality. Good data leads to fair, accurate, and helpful results. Bad data leads to flawed systems that can do more harm than good.
The Human Role in Data Science
Even though machines are doing the heavy lifting, humans still play a big role in the data science process. Data scientists don’t just collect data and run it through models—they ask the right questions, interpret results, and adjust models based on real-world feedback.
Let’s say you’re building an app that predicts whether customers will cancel their subscription. A machine might suggest certain actions based on patterns it sees, but it’s a human who decides whether those suggestions make sense, whether they’re ethical, and how to present them to users.
This partnership between human insight and machine intelligence is key. It ensures that the systems we build are not just smart, but also responsible and aligned with human values.
What’s Coming Next
Looking ahead, the role of data science data will only grow. As we generate more data from smart devices, wearables, and digital platforms, the potential for intelligent systems will expand. In the near future, we’ll see even more personalized experiences—apps that know what you want before you do, healthcare systems that detect illness early, and virtual assistants that truly understand you.
But this future also comes with responsibility. We’ll need stronger data privacy laws, better transparency from tech companies, and more public awareness about how data is used. The smarter our systems get, the more careful we must be in building and managing them.
Conclusion: Data Is Power, But People Still Matter
In the end, data science data is more than just numbers and spreadsheets. It’s the building block of today’s smartest technologies. It helps businesses grow, cities function better, and people live healthier lives. But it also needs care, responsibility, and human guidance to be used wisely.
As users, we’re not just consumers of technology—we’re also contributors to the data that shapes it. Every click, search, or interaction adds to the stream of knowledge that powers the digital world. The more we understand how that data works, the more empowered we are to shape the future.
So, whether you’re a student, a business owner, a developer, or just someone curious about the future, one thing is clear—data is here to stay. And if we use it right, it can do incredible things.
Frequently Asked Questions (FAQ)
1. What is data science data?
Answer:
Data science data refers to the large sets of information that data scientists use to train, test, and improve algorithms. It includes structured data like numbers and dates, and unstructured data like text, images, and videos. This data helps machines learn and make smart predictions.
2. How is big data connected to data science?
Answer:
Big data provides the raw material that powers data science. Without big data, data science wouldn’t work. It allows machines to learn patterns, spot trends, and make accurate decisions across industries—from healthcare to finance to e-commerce.
3. What are some real-life examples of data science using big data?
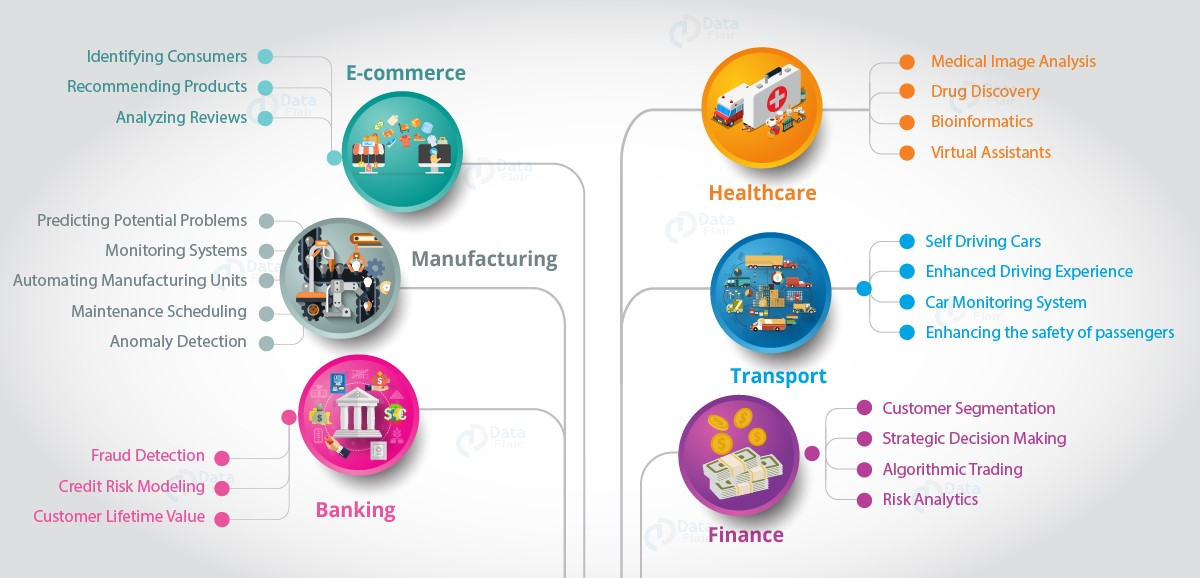
Answer:
Some everyday examples include:
- Netflix recommending shows based on your watch history.
- Google Maps predicting traffic based on real-time GPS data.
- Amazon suggesting products based on browsing behavior.
All of these rely on big data and data science working together.
4. How do smarter algorithms help in daily life?
Answer:
Smarter algorithms simplify tasks. They:
- Predict your interests on social media.
- Detect fraud in online banking.
- Translate languages instantly.
These improvements come from analyzing massive datasets over time.
5. Is big data the same as data science?
Answer:
Not exactly. Big data is the large volume of information. Data science is the process of analyzing that data. Data scientists turn raw data into insights using tools like machine learning, statistics, and visualization techniques.
6. Why is “data science data” important for companies?
Answer:
Companies rely on data science data to make smart choices. It helps them:
- Understand customer needs.
- Optimize supply chains.
- Detect risks early.
Without it, many modern businesses would struggle to compete.
7. What tools are used in data science?
Answer:
Some common tools include:
- Python and R for programming.
- Pandas and NumPy for handling data.
- Tableau and Power BI for visualization.
- TensorFlow for machine learning.
These tools help process and visualize data for better decisions.
8. How do algorithms learn from data?
Answer:
Algorithms learn by spotting patterns. For example, if you feed them thousands of pictures of cats and dogs, they begin to understand the difference between the two. Over time, the more data they get, the better they become at making predictions.
9. Can bad data affect results?
Answer:
Absolutely. Poor-quality data leads to poor results. This is often called “garbage in, garbage out.” That’s why data cleaning and validation are critical steps in any data science project.
10. What industries use data science data the most?
Answer:
Almost every major industry uses it today. Some top examples include:
- Finance: fraud detection, stock prediction.
- Healthcare: diagnosis support, patient data analysis.
- Retail: product recommendations, inventory tracking.
- Marketing: customer targeting, ad optimization.
11. Is data science only for big companies?
Answer:
No. While big companies lead in using data science, small and medium businesses also benefit. With affordable cloud tools and open-source software, even startups can use data science data to grow smarter.
12. What is the future of data science and big data?
Answer:
The future is bright. As data keeps growing, smarter and more ethical algorithms will emerge. We’ll see more automation, better predictions, and stronger decision-making tools powered by data science data.
13. Do I need to learn coding to get into data science?

Answer:
Not always. While coding helps, many tools now offer no-code or low-code options. You can start with basic tools and grow into more advanced skills like Python or SQL over time.
14. How do companies collect so much data?
Answer:
Companies gather data through websites, apps, transactions, sensors, and customer feedback. Every time you click, swipe, or buy something online, you’re adding to the pool of data science data.
15. How can I start learning about data science and big data?
Answer:
Start small. There are free courses on platforms like Coursera, edX, or YouTube. Learn about data basics, visualization, and simple coding. Practice with real datasets from Kaggle or government open data portals.
Bonus Insight
If you’ve ever wondered why your favorite music app always seems to know what you like, or how your bank catches fraud so fast, the answer lies in how data science data and algorithms work behind the scenes. The smarter the data, the smarter the system.
External Source
https://www.kdnuggets.com/2016/11/big-data-data-science-explained.html